Google Erases Thousands of Links, Tricked By Phony Complaints
Dubious copyright claims citing 1998 law led the search giant to make unfavorable articles vanish. Google Erases Thousands of Links, Tricked by Phony Complaints
A Google search, at one time, could locate a news article on a man accused of attempted child rape, another on someone charged with fraud and still others on Ukrainian politicians facing corruption allegations. Googling certain keywords in March would find an article detailing the movements of two coronavirus-infected British tourists in Vietnam and warning others who visited the same places to take precautions.
Then the stories vanished.
Google stopped listing them in searches after it received formal requests that it scrub links to the pieces, a Wall Street Journal investigation found.
The Journal identified hundreds of instances in which individuals or companies, often using apparently fake identities, caused the Alphabet Inc. unit to remove links to unfavorable articles and blog posts that alleged wrongdoing by convicted criminals, foreign officials and businesspeople in the U.S. and abroad.
Google took them down in response to copyright complaints, many of which appear to be bogus, the Journal found in an analysis of information from the more than four billion links sent to Google for removal since 2011.
Google’s system was set up to comply with the Digital Millennium Copyright Act, or DMCA. The 1998 law gives tech firms immunity from claims in copyright cases as long they quickly take down copyrighted material once alerted.
Takedown requests to Google are often from media companies legitimately requesting that pirated copies of a movie or album be removed from search results. Publishers and news outlets, including the Journal, have also asked Google to scrub allegedly infringing material from Google Search.
Yet some requests, the Journal found, appear to be from people manipulating the system in ways it didn’t intend, resulting in Google’s taking down lawful content.
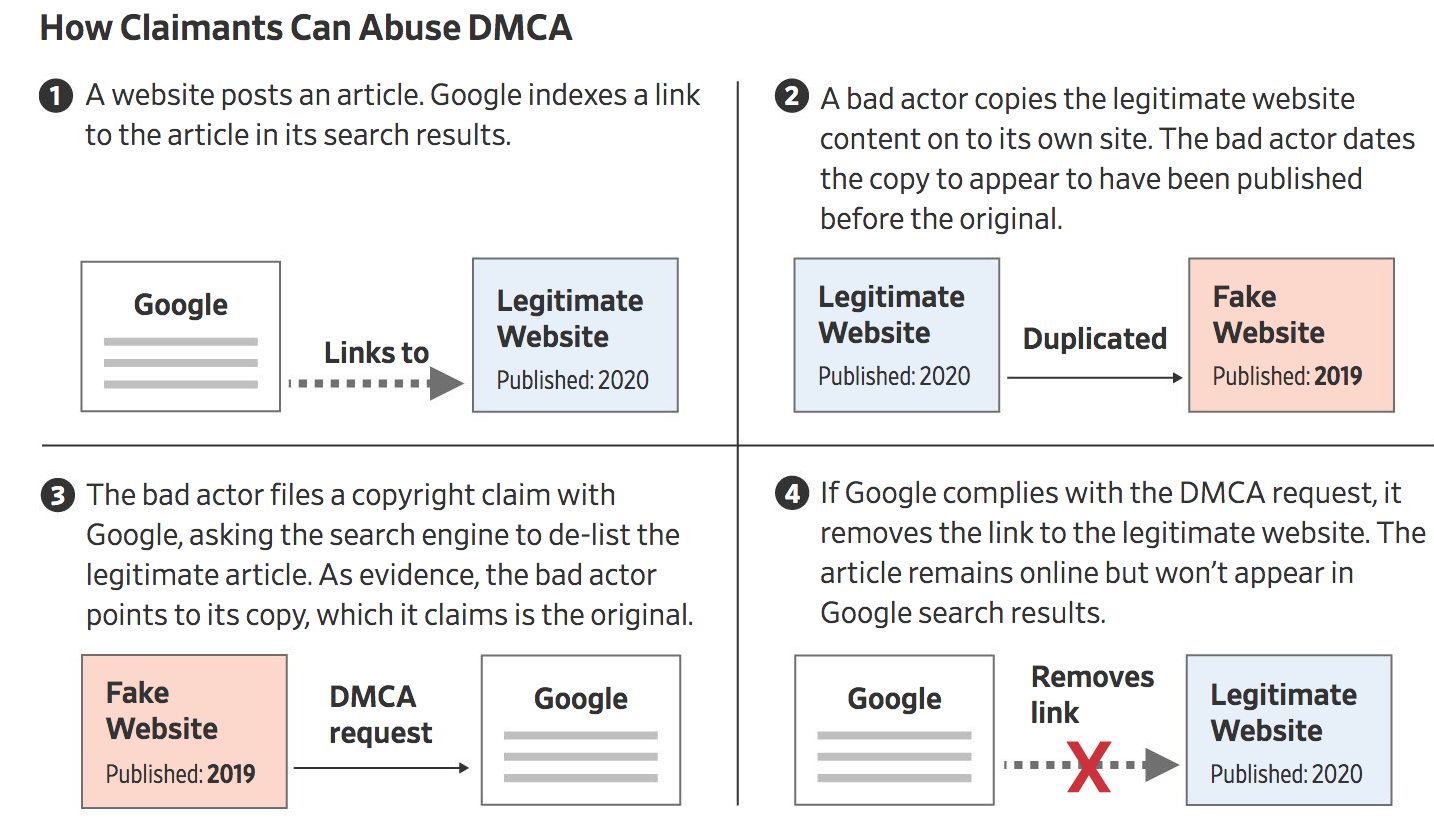
When a Colorado man, Dak Steiert, faced state-court charges of running a fake law firm in 2018, he sent Google a series of copyright claims against blogs and a law-firm website that discussed his case, claiming they had copied the posts from Mr. Steiert’s own website. That wasn’t true, the Journal determined, but Google erased the pages from its search engine anyway.
Last year, Mr. Steiert, who didn’t respond to requests for comment, pleaded guilty in Colorado state court to one count of false advertising in his business. The Colorado Supreme Court closed his practice. The articles remained invisible in Google searches until the Journal flagged the cases to Google, which then reinstated the links.
When Google erases links to an article in its search engine, it is often the equivalent of wiping the piece from the internet, even though the item may still exist on a little-trafficked website. Searchers won’t see a trace.
“If people can manipulate the gatekeepers to make important and lawful information disappear,” said Daphne Keller, a former Google lawyer and now a program director at Stanford University’s Cyber Policy Center, “that’s a big deal.”
Google has automated much of the process of reviewing takedown requests, relying on techniques that don’t require human review, to enable removals at a large scale, said company spokeswoman Lara Levin.
After the Journal shared its findings with Google, the company conducted a review and restored more than 52,000 links it determined it had improperly removed, she said. Google said its review identified more than 100 new abusive submitters, declining to discuss individual cases.
Google “aims to strike a balance between making it easy and efficient for rightsholders to report infringing content while also protecting free expression on the web,” Ms. Levin said, adding that “there are bad actors who attempt to abuse the system” and that Google works to fight such abuse.
Congress enacted the DMCA when internet companies were smaller—Google was founded the same year. Now companies such as Alphabet, Amazon.com Inc. and Facebook Inc. are giants, and some lawmakers have begun calling for more regulation of them as evidence mounts that the companies aren’t self-policing their platforms.
Tech companies have pledged to make changes and have opposed government intervention, saying they aren’t legally responsible for content others post on their sites. Google has said it functions as a reference—an argument suggesting it acts like a phone book.
The DMCA takedown system could soon come under further scrutiny. The U.S. Copyright Office will soon conclude a yearslong study into how well DMCA is working, said a person familiar with the study. Google executives have said in meetings with government agencies and in public comments that overhauling the takedown-notice process isn’t necessary and that the process is an effective, efficient and balanced approach because it allows free expression and creativity to flourish across the internet, Google’s Ms. Levin said.
Signs of fakery
Google users who file copyright complaints through the company’s online portal must check a box swearing under penalty of perjury that they are the real copyright owners or authorized to act on the owner’s behalf. Through the portal, users submit links to infringing material and copyrighted works.
A Google search for reputation managers turns up firms claiming to be able to remove negative content from popular search engines including Google—even though typically Google only removes links for alleged copyright violations or to comply with other relevant laws.
The Journal dug into the world of takedown requests by reviewing electronic records of copyright-removal notices that Google shares with Harvard University researchers. The Journal cross-referenced those requests with separate data Google releases regularly in a “transparency report,” which discloses whether it granted each request.
The Journal then reviewed thousands of these takedown requests for signs of potential fakery, individually examining those that mentioned plagiarized news articles, copyright violations on pages of well-known websites such as Yelp, or contained other characteristics that can be legitimate but which the Journal found are common in questionable complaints.
Scrutinizing information on the senders, the Journal identified signs of phony complaints: names of people that couldn’t be confirmed, photos of ostensible senders that were cribbed from the internet, blogs claiming to have been violated that had only a few posts, and phony claims to ties with legitimate publications.
The Journal also interviewed dozens of people who filed takedown requests or were the subject of them, as well as current and former Google employees.
Google’s reinstatements included more than 400 link removals the Journal flagged as suspicious, including all the examples in this article. Google said it also reinstated thousands of others it traced to many of the same senders.
Financial-news site Benzinga fell victim to a common tactic to trick Google: backdating. Someone wanting Google to hide a webpage will find a little-trafficked blog and post a copy of the content from the legitimate webpage. After backdating the plagiarized post, the complainant will file an electronic notice with Google claiming the real article is a copyright violation.
Benzinga, after publishing an August 2015 article about financial difficulties at publicly traded Amira Nature Foods Ltd., began getting emails demanding it take the story down, said its managing editor, Jason Shubnell. The emails came from three different names, including a Richa Parikh who wrote that the Amira article was “spoiling our online reputation” and offered to pay Benzinga to remove it, according to a copy of an email the Journal reviewed.
Benzinga largely ignored the emails. In 2018, Google wiped the Benzinga story from its search results after a blog masquerading as CNN made a copyright claim. Mr. Shubnell said Benzinga wasn’t aware Google had hidden its story until the Journal contacted it, adding: “There was nothing wrong with the actual content of the article.”
Amira didn’t respond to requests for comment. CNN, a unit of AT&T Inc.’s WarnerMedia, said: “When bad actors or bogus sites are identified, our legal team takes swift action.”
Backdating also appeared to trick Google into purging the article on the two Britons with Covid-19. The story appeared on a Vietnamese-government affiliated news website on March 9, naming the hotel, bars and restaurants the tourists visited and urging readers who patronized the establishments to take precautions.
Google removed search links to the Vietnamese-language article after someone identifying as Long Hoang filed a complaint claiming the piece violated the copyright on an identical blog post about the tourists dated October 20, 2019, more than four months before the unnamed Britons visited. The blog consists of only eight posts, all cited in copyright complaints filed with Google. The complainant and news site didn’t respond to inquiries.
After the Journal brought the example to Google’s attention in May, Google reinstated the link, as well as more than 100 others it said were related to other abusive submitters.
Flood of claims
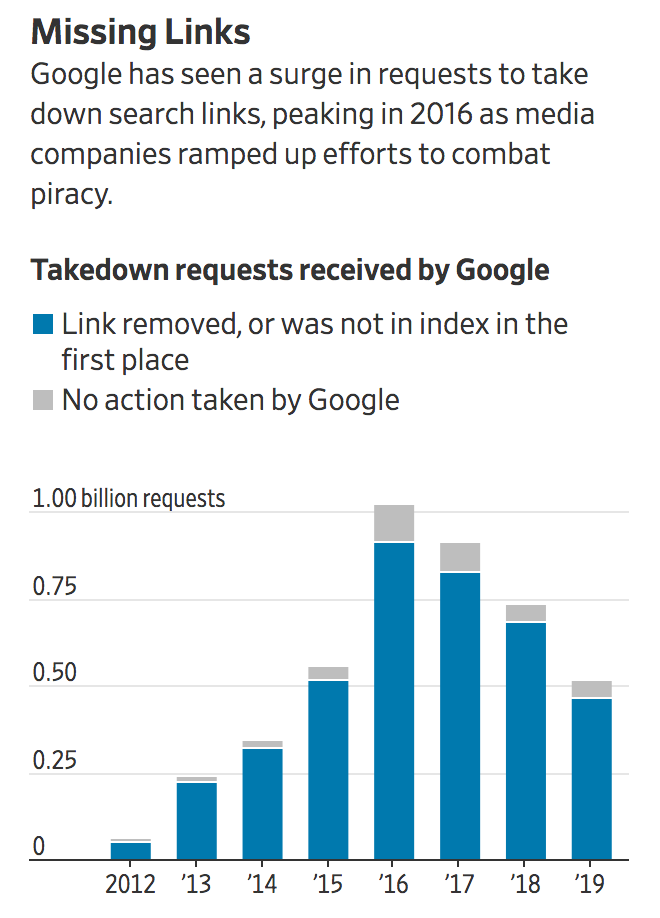
Google has struggled to keep up with the flood of claims, said the current and former Google employees. Between 2002 and 2010, Google received copyright requests pertaining to fewer than 100,000 pages across web search and several other platforms, according to data Google shares with Harvard’s Berkman Klein Center for Internet & Society. Now, Google routinely deals with more than one million requests a day.
Google’s website says that when it receives a copyright request, its teams “carefully review” it for completeness and other issues. The current and former employees said Google has only about 100 workers reviewing requests world-wide and largely relies on its automated system to weed out bogus requests.
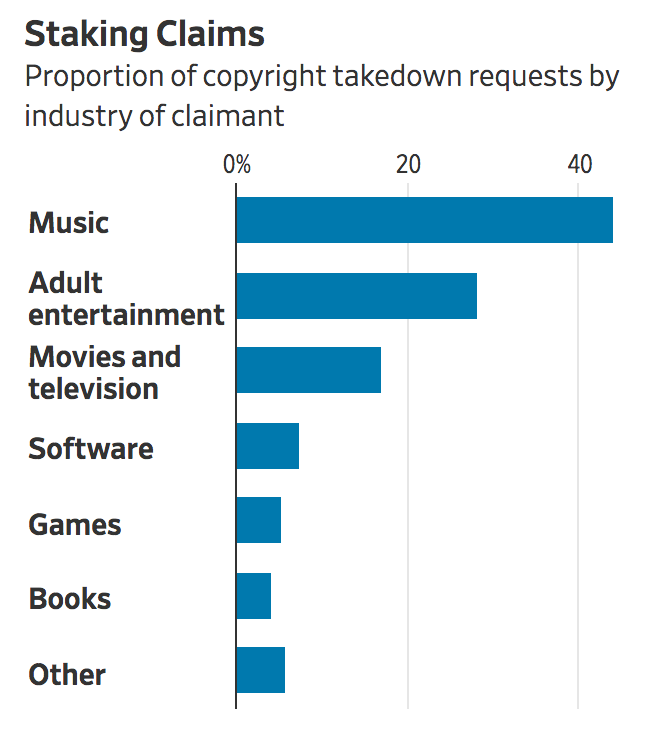
Last year, Google removed nearly 80% of the 240 million links in its search catalog that were flagged for copyright violations, its transparency report shows. Antipiracy firms that file requests to take down hundreds of millions of URLs on behalf of media companies rank among the top DMCA requesters, the report shows.
University of California, Berkeley law professor Jennifer Urban and her colleagues found in 2017 that as many as one third of the takedown requests to Google made claims that might not stand up in court.
Google’s Ms. Levin said that, in addition to its automated system, the company counts on copyright owners whose work is frequently infringed upon to report problems. She said the number of links reported through the DMCA process has fallen from a 2016 peak and many requests are for websites Google hasn’t cataloged.
Google’s algorithms also take into account the number of requests parties make, Ms. Levin said: If a website receives a large number of valid takedown notices, the site might appear lower overall in search results.
The Journal found more than a dozen other cases in which supposed media outlets, with names like Arctic Times and Palmdale Herald, got Google to remove links from prominent local news sites and other pages that alleged wrongdoing in recent years. The only trace left was a notice at the bottom of the search screen indicating some results had been removed because of copyright violations.
The articles Google removed included a roughly decade-old newspaper article about a Seattle-area man accused of attempted rape after he allegedly tried to solicit sex from a child online. Also hidden: a piece about a former online-university dean who faced criminal charges for allegedly borrowing federal student loans with a stolen Social Security number. Neither man responded to requests for comment.
Google’s Ms. Levin said “the vast majority of DMCA removals come from reporters who have a track record of valid, non-abusive takedowns.”
Search engines aren’t required under the law to notify takedown targets, although some sites such as Yelp say Google typically gives them a heads-up when it scrubs content. Ms. Levin said the company sends removal notices to website owners registered with its “search console,” a tool for connecting with Google.
The Journal found at least one case in which Google declined to put back a post from a blogger who complained about a fraudulent takedown request. The claim targeted her post about an investment firm facing regulatory scrutiny. The post was among those Google reinstated after the Journal pointed them out.
 Russian Factor
Russian Factor
The Journal found a cluster of requests concerning prominent officials in Ukraine. Google removed dozens of links to critical Russian-language posts—unfavorable content about members of Ukraine’s parliament, alleged mob members, and other government officials and businesspeople—after requesters claimed the articles were ripped off from blogging platforms Medium and LiveJournal, the Journal found.
Several of the LiveJournal accounts used names and photos of people who said they had nothing to do with the blogs. One LiveJournal account falsely claimed to be a Russian edition of Newsweek and contained the magazine’s logo.
Newsweek Chief Executive Dev Pragad called the account “alarming” after the Journal pointed it out.
Jamie Judson, an artist in Northglenn, Colo., didn’t know her old LiveJournal account had been taken over by someone writing in Russian as part of an apparent takedown ruse until the Journal notified her.
In the 2000s, she used her online LiveJournal diary to write about Japanese comics, abandoning it years before Russian-language posts began appearing on her pages several years ago. The posts, about a businessman with alleged ties to organized crime in the Ukrainian city of Odessa, appear to be plagiarized from content first published by other websites in 2017. Attempts to reach the businessman weren’t successful.
A person using the name Aleksandr Lesnoy asked Google in 2019 to remove the stories, pointing to the posts on Ms. Judson’s LiveJournal page. Ms. Judson doesn’t speak Russian and, after the Journal told her of the posts, discovered she was locked out of her account. “Obviously I can’t read a word of it,” she said. “Had I discovered it on my own, I wouldn’t even know what the posts were about.”
After the Journal contacted LiveJournal about Ms. Judson, the platform restored her control over the account, deleted the Russian-language posts and sent her a password-reset link.
The Journal found that last year someone had targeted for takedown several articles by the Mykolaiv Center for Investigative Reporting in Ukraine, an affiliate of a U.S.-based nonprofit, the Global Investigative Journalism Network. The articles focused on two politically connected businessmen who allegedly profited from financial corruption.

The takedown requests listed an Igor Danilov who claimed the investigative articles were copies of his LiveJournal posts. A real Ukrainian journalist named Igor Danilov said he didn’t create the LiveJournal posts or submit the Google takedown requests.
After the Journal contacted the investigative-journalism center’s editor, Oleg Oganov, he filed copyright counterclaims with Google, which reinstated the links. “It is very unfair,” he said. “We worked hard to reveal corruption and injustice…but Google corporation can easily ban our story.”
Rambler Group, a Russian internet-search and media company that owns LiveJournal, said it wasn’t aware of the misuse of its platform to trick Google until the Journal presented its findings.
Among people in the U.S. who got Google to take down articles is Cara Daggett, a Virginia Tech assistant professor of political science. After a website named Campus Reform—it chronicles what it sees as colleges’ liberal bias—quoted heavily from her 2018 paper about how male misogyny can lead to climate change, she was bombarded with angry, sexist tweets and emails, she said.

She filed a copyright complaint with Google, which removed the Campus Reform article from search. Ms. Daggett said she “made the request to Google because it was plagiarism that led to harassment.”
Cabot Phillips, editor in chief of Campus Reform, said the site wasn’t aware Google took the article down from search, which Mr. Phillips said editors would have wanted to know about. The article was among those Google restored after the Journal pointed them out.
“I understand that Google gets to decide what content goes where,” Mr. Phillips said. “But it’s dangerous to provide themselves as a hub of information and be picking and choosing which information is comfortable.”
Related Articles:
Ad Agency CEO Calls On Marketers To Take Collective Stand Against Facebook (#GotBitcoin?)
Facebook Bug Potentially Exposed Unshared Photos of Up 6.8 Million Users (#GotBitcoin?)
Facebook Finds Security Flaw Affecting Almost 50 Million Accounts (#GotBitcoin?)
Alert! 540 Million Facebook Users’ Data Exposed On Amazon Servers (#GotBitcoin?)
Facebook Bug Potentially Exposed Unshared Photos of Up 6.8 Million Users (#GotBitcoin?)
Facebook Says Millions of Users’ Passwords Were Improperly Stored in Internal Systems (#GotBitcoin?)
Advertisers Allege Facebook Failed to Disclose Key Metric Error For More Than A Year (#GotBitcoin?)
Ad Agency CEO Calls On Marketers To Take Collective Stand Against Facebook (#GotBitcoin?)
Thieves Can Now Nab Your Data In A Few Minutes For A Few Bucks (#GotBitcoin?)
New Crypto Mining Malware Beapy Uses Leaked NSA Hacking Tools: Symantec Research (#GotBitcoin?)
Equifax, FICO Team Up To Sell Your Financial Data To Banks (#GotBitcoin?)
Cyber-Security Alert!: FEMA Leaked Data Of 2.3 Million Disaster Survivors (#GotBitcoin?)
DMV Hacked! Your Personal Records Are Now Being Transmitted To Croatia (#GotBitcoin?)
Lithuanian Man Pleads Guilty In $100 Million Fraud Against Google, Facebook (#GotBitcoin?)
Hack Alert! Buca Di Beppo, Owned By Earl Enterprises Suffers Data Breach Of 2M Cards (#GotBitcoin?)
SEC Hack Proves Bitcoin Has Better Data Security (#GotBitcoin?)
Maxine Waters (D., Calif.) Rises As Banking Industry’s Overseer (#GotBitcoin?)
Leave a Reply
You must be logged in to post a comment.